
AWS Glue Explained: What It Is, How It Works, Use Cases, and Cost Optimization Strategies
Data is the lifeblood of modern enterprises. Yet, managing it — collecting from disparate sources, transforming it into usable formats, and loading it into analytics-ready destinations — remains one of the most complex and resource-intensive challenges IT teams face. That is precisely where AWS Glue steps in as a game-changer.
In 2024, the global ETL tools market reached $7.6 billion and is projected to exceed $22 billion by 2032. The broader data integration market is on pace to grow from $17.6 billion in 2025 to over $33 billion by 2030. These figures underscore a clear signal: organizations worldwide are prioritizing seamless, automated data integration — and AWS Glue sits at the center of that shift.
This comprehensive guide covers everything you need to know: what AWS Glue is, how it works, its standout features and components, real-world use cases, pros and cons, alternatives, and smart strategies to control costs. Whether you are a data engineer evaluating AWS Glue for the first time or an enterprise looking to optimize existing pipelines, this blog has you covered.
What Is AWS Glue? The Serverless ETL Service Explained
AWS Glue is a fully managed, serverless ETL (Extract, Transform, and Load) data integration service provided by Amazon Web Services. It is designed to simplify and automate the entire process of discovering, preparing, and combining data for application development, machine learning (ML), and analytics — without requiring you to manage any underlying infrastructure.
At its core, AWS Glue streamlines data integration by:
- Extracting data from over 100 diverse sources — including Amazon S3, Amazon Redshift, RDS, and even external systems like Azure Data Lake.
- Transforming data through schema discovery, cleansing, enrichment, and normalization.
- Loading the processed data into data lakes, data warehouses, databases, or lakehouses for analytics and reporting.
Amazon describes AWS Glue as an easy and cost-effective way to categorize, clean, enrich, and transfer data efficiently between different data streams and stores. Its serverless architecture means you pay only for the resources you use, with no long-term contracts and no infrastructure to maintain.
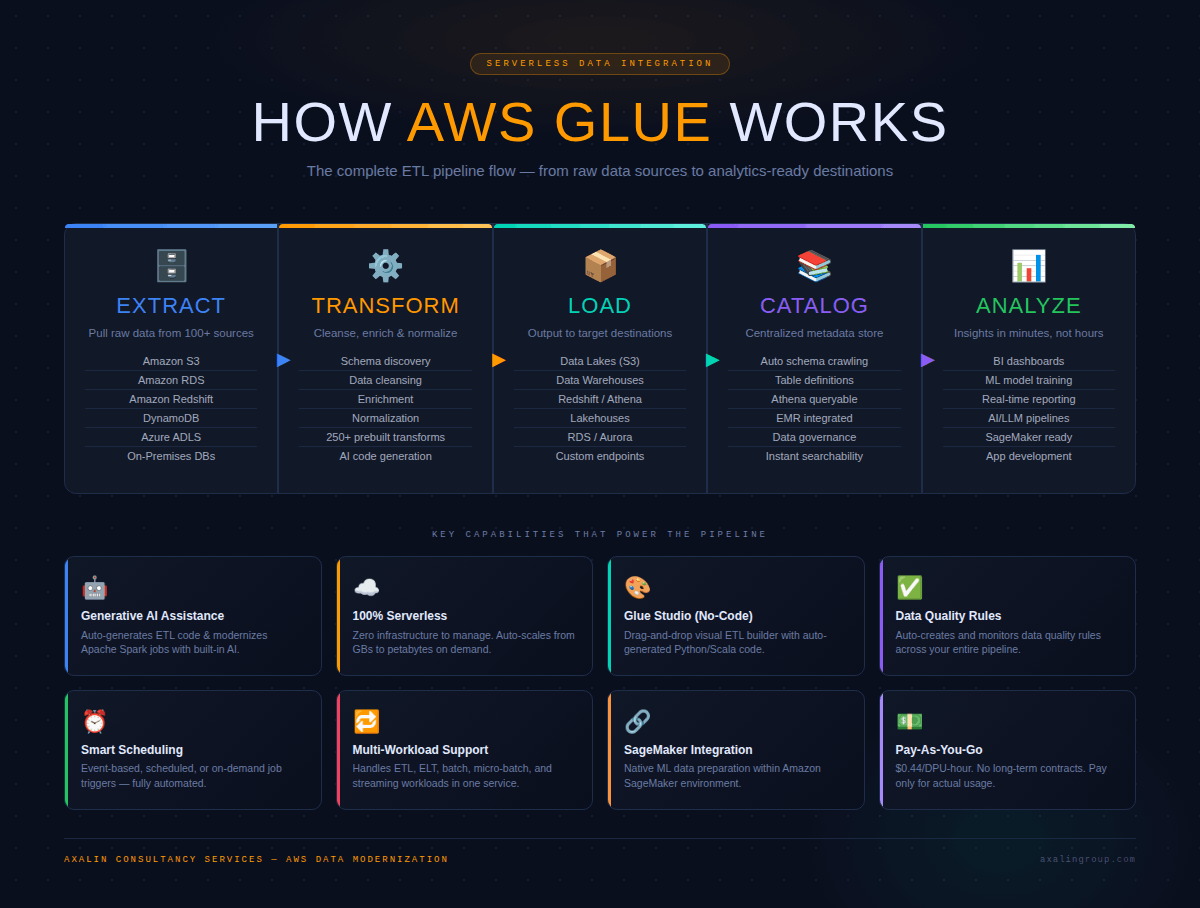
How Does AWS Glue Work? Understanding Data Integration in AWS
Before diving into AWS Glue's features, it helps to understand what data integration actually means. Data integration is the process of consolidating data from multiple, often heterogeneous sources into a unified, analytics-ready format. It involves identifying source data, cleaning and normalizing it, merging datasets, and loading the output into a destination system — be it a data warehouse, a data lake, or a real-time dashboard.
AWS Glue automates every step of this workflow. Instead of writing custom scripts or managing Spark clusters, you define your data sources and targets, and AWS Glue takes care of the rest — including auto-generating ETL code in Python or Scala, discovering schema changes, scheduling jobs, and monitoring runs.
Its multi-faceted architecture powers this through several key components working in concert.
AWS Glue Components: A Deep Dive
Understanding the components of AWS Glue is essential for anyone evaluating or implementing it. Here is a breakdown of its core building blocks:
AWS Glue Data Catalog
This is the central metadata repository of AWS Glue. It automatically crawls your data sources to discover schemas and stores that metadata as table definitions. The cataloged data becomes instantly queryable using Amazon Athena, Amazon Redshift Spectrum, and Amazon EMR — giving your teams a unified, searchable view of all data assets without physically moving the data.
AWS Glue Studio
AWS Glue Studio is a visual interface that enables no-code and low-code ETL job creation. Data engineers can visually build, run, and monitor ETL pipelines using a drag-and-drop editor. AWS Glue auto-generates the underlying Scala or Python code, dramatically accelerating pipeline development — even for teams with limited coding expertise.
AWS Glue DataBrew
DataBrew is a visual data preparation tool that allows users to interact directly with data from S3, Redshift, RDS, Aurora, and AWS Lake Formation. It comes with over 250 prebuilt transformations to automate data preparation tasks — from filtering anomalies and correcting invalid values to standardizing data formats.
AWS Glue Data Quality
This component automatically creates, manages, and monitors data quality rules throughout your data lakes and pipelines. It ensures your data remains accurate, complete, and reliable — a foundational requirement for trustworthy analytics and AI workloads.
The AWS Glue Console
The management console is where you orchestrate your entire workflow. From here, you define AWS Glue objects, edit transformation scripts, set event triggers, schedule jobs, and monitor pipeline performance — all from a single, centralized interface.
Key Features of AWS Glue: What Can the AWS Data Integration Service Do?
AWS Glue is a feature-rich platform built for modern data engineering demands. Here are its most impactful capabilities:
- Automated ETL Job Execution: AWS Glue can trigger ETL jobs automatically when new data arrives in your Amazon S3 buckets eliminating manual intervention and enabling real-time data pipelines.
- Multi-Method Support: Supports a variety of processing approaches including ETL, ELT, batch processing, micro-batch, and streaming workloads. Teams can work in their preferred method — drag-and-drop, notebook, or code.
- Generative AI Assistance: AWS Glue offers AI-powered code generation for ETL authoring, automated Spark job modernization, and intelligent Spark troubleshooting — accelerating development cycles significantly.
- Amazon SageMaker Integration: With the next generation of Amazon SageMaker, AWS Glue integrates seamlessly for data processing projects, enabling shared management and monitoring across Glue, Athena, EMR, and MWAA.
- AWS Glue Interactive Sessions: Data engineers can interactively explore and prepare data using their preferred IDE or notebook — enabling faster experimentation without spinning up dedicated clusters.
- Cross-Platform Connectivity: AWS Glue connects to Amazon S3, Redshift, RDS, DynamoDB, and even external platforms like Azure Data Lake Storage, making it highly versatile in hybrid and multi-cloud environments.
AWS Glue Use Cases: When Should You Use It?
AWS Glue is purpose-built for organizations dealing with large volumes of data from multiple sources. Here are the most common and impactful use cases:
Simplifying ETL Pipeline Management
Organizations managing complex data workflows benefit enormously from AWS Glue's automatic provisioning and worker management. By removing infrastructure overhead, teams can consolidate all data integration needs into a single, fully managed service — freeing engineers to focus on higher-value work.
Building Analytics and Reporting Pipelines
AWS Glue accelerates the preparation and loading of data into data lakes and warehouses like Amazon Redshift, enabling faster business intelligence and reporting cycles. Data that previously took hours to prepare can be made analytics-ready in minutes.
Machine Learning Data Preparation
Preparing training data for ML models is one of the most time-consuming steps in the AI pipeline. AWS Glue's integration with Amazon SageMaker and its data transformation capabilities make it an ideal tool for discovering, cleaning, and engineering features from raw datasets.
Real-Time and Streaming Data Processing
AWS Glue supports streaming workloads, allowing organizations to process continuous data streams alongside batch jobs. This makes it suitable for use cases such as real-time event processing, IoT data ingestion, and live fraud detection pipelines.
Multi-Cloud and Hybrid Data Discovery
With support for on-premises, AWS, and even Azure data sources, AWS Glue helps organizations quickly identify and make data available for querying and transformation — regardless of where it resides. This is critical for enterprises operating in hybrid or multi-cloud environments.
Benefits of AWS Glue: Why Organizations Choose It
The adoption of AWS Glue continues to accelerate — and for good reason. Here are the core benefits driving that growth:
- Accelerated Data Pipeline Development: AWS Glue provides a fully managed, serverless toolkit to design and automate modern data pipelines with built-in ETL, schema discovery, and cross-service integration — reducing development time from weeks to days.
- On-Demand Scalability: AWS Glue automatically scales from gigabytes to petabytes to handle even the most resource-intensive jobs. No capacity planning is required, and you pay only for the resources you actually consume.
- Reduced Operational Complexity: By eliminating infrastructure management, AWS Glue allows your data engineering teams to focus on designing intelligent workflows rather than maintaining servers, clusters, or runtime environments.
- Pay-As-You-Go Pricing: Unlike traditional ETL platforms with licensing fees and long-term contracts, AWS Glue charges based on actual usage — measured in Data Processing Units (DPUs) at $0.44 per DPU-hour.
- Generative AI Capabilities: Built-in AI assistance modernizes legacy Apache Spark jobs, generates ETL code intelligently, and offers troubleshooting guidance — democratizing data engineering across skill levels.
- Unified Data Catalog: A centralized, searchable catalog provides complete visibility into all data assets — making it easier to govern, discover, and reuse data across teams and workloads.
AWS Glue Pros and Cons: An Honest Assessment
As with any technology, AWS Glue has both genuine strengths and real limitations. Here is an objective breakdown:
Pros
- Serverless architecture — no infrastructure to manage or maintain
- Automatic ETL code generation in Python or Scala accelerates workflow development
- Glue Data Catalog provides centralized data visibility and governance
- Developer endpoints allow engineers to test and customize ETL scripts
- Flexible job scheduling supports event-based, scheduled, and on-demand triggers
- Seamless AWS ecosystem integration with S3, Redshift, Athena, EMR, and SageMaker
Cons
- Technical barrier — requires working knowledge of Apache Spark, Python, or Scala
- Limited language support — only Python and Scala are supported for ETL scripting
- AWS-centric — integration outside the Amazon ecosystem can be complex
- Cold start latency — Glue jobs can experience startup delays compared to always-on solutions
- Cost at scale — without proper governance, expenses can grow quickly on large or poorly optimized workloads
Understanding these trade-offs is essential for making an informed decision. Organizations with complex, large-scale pipelines may need to complement AWS Glue with other services or expert guidance to maximize its value.
AWS Glue vs EMR and Other Alternatives: How Do They Compare?
AWS Glue is not the only data processing service in the AWS ecosystem. Knowing when to use Glue versus its alternatives is key to building cost-effective, performant data architectures:
- AWS EMR (Elastic MapReduce): Best suited for heavy big data and ML workloads that require full control over Spark or Hadoop clusters. EMR is often cheaper than Glue at scale but demands more configuration and ongoing operational management.
- AWS Step Functions: An AWS-native workflow orchestration service ideal for coordinating Glue jobs, Lambda functions, and other services within event-driven pipelines. It complements rather than replaces Glue.
- Apache Airflow: A popular open-source orchestration tool frequently used alongside AWS Glue. It excels at chaining tasks across multiple services but requires ongoing maintenance and DevOps expertise.
- Amazon Redshift: While Redshift can handle some ETL scenarios — particularly for real-time streaming and event-driven workloads — it does not offer the same breadth of flexibility in data preparation across varied source types that Glue provides.
- Amazon Athena: A serverless SQL query service that lets you run queries directly on S3. It is simpler and cost-effective for ad hoc queries but is not a complete ETL solution.
- AWS Kinesis: Designed for high-volume, low-latency real-time data streams. Kinesis is complementary to Glue rather than a direct replacement, particularly useful when pipelines involve live streaming data.
Since AWS Glue is serverless, it tends to carry a higher per-unit cost than self-managed services like EMR. The right choice depends on your scale, team expertise, and how much operational overhead you are willing to manage.
AWS Glue Cost Optimization: How to Reduce Your Cloud Data Integration Spend
AWS Glue's pay-as-you-go model is convenient, but it can become expensive without careful management. At $0.44 per DPU-hour, large or long-running ETL jobs add up fast — particularly when jobs are over-provisioned or configured to reprocess data unnecessarily. Organizations commonly find themselves with bills running into thousands of dollars per month from poorly optimized pipelines.
Here are proven strategies to optimize AWS Glue costs:
- Right-size your DPUs: Analyze your jobs' actual resource consumption and allocate DPUs accordingly. Enable auto-scaling so Glue dynamically adjusts resources based on workload, avoiding over-provisioning on lighter tasks.
- Use job bookmarks: Job bookmarks track previously processed data, preventing AWS Glue from reprocessing the same records on subsequent runs. This single optimization can dramatically reduce both execution time and cost.
- Offload lightweight queries: For simple, ad hoc data querying, use Amazon Athena or Redshift Spectrum instead of spinning up full Glue jobs. Reserve Glue for complex transformation workloads that truly need it.
- Schedule batch jobs strategically: Run batch jobs during off-peak hours when feasible. Consolidate smaller, frequent jobs into larger, less frequent batch runs to maximize DPU utilization.
- Monitor spend continuously: Amazon does not natively provide granular Glue cost breakdowns by job, team, or feature. Use cost intelligence tools to track Glue spend at a fine-grained level, detect anomalies early, and allocate costs accurately across teams or products.
Proactive cost governance transforms AWS Glue from a potential budget liability into a highly efficient, cost-justified service — especially at enterprise scale.
Frequently Asked Questions About AWS Glue
Is AWS Glue good for ETL?
Yes. AWS Glue is specifically designed as a fully managed ETL service. It simplifies data preparation and loading for analytics, allowing you to create and run ETL jobs in minutes via the AWS Management Console — without managing any underlying infrastructure.
What is AWS Glue used for?
AWS Glue is used to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning, and application development. It supports batch, micro-batch, and streaming workloads across a wide range of AWS and third-party data stores.
Why use AWS Glue over Lambda?
AWS Glue handles large-scale, long-running data workloads far more efficiently than Lambda. While Lambda has a 15-minute execution timeout, AWS Glue jobs can run for hours. Additionally, Glue uses Apache Spark's parallel processing capabilities, making it significantly faster for big data transformation tasks.
What language does AWS Glue use?
AWS Glue ETL scripts are written in Python or Scala. Glue Studio also supports no-code visual job creation, automatically generating the underlying scripts so less experienced users can build pipelines without writing code.
Can AWS Glue connect to Azure?
Yes. Through the Azure Data Lake Storage Connector for AWS Glue, the service can extract data from Azure Data Lake Storage Gen2 (ADLS) and load data back into Azure — enabling cross-cloud data pipelines for hybrid cloud architectures.
When should you not use AWS Glue?
AWS Glue may not be the right fit when you need tight control over Spark cluster configuration, require very low latency (consider Kinesis instead), operate primarily outside the AWS ecosystem, or have very simple querying needs that Athena can handle more cost-effectively.
Partner With Axalin for Expert AWS Glue and Data Modernization Services
Understanding AWS Glue is one thing — unlocking its full potential for your specific business context is another. That is where Axalin comes in.
Axalin is a premier AWS cloud partner delivering end-to-end Data Modernization and Cloud Adoption services as part of its comprehensive Digital Transformation portfolio. With a leadership team boasting over 50 years of combined IT service delivery experience, Axalin has helped organizations across Finance & Banking, Healthcare, E-commerce, Logistics, Manufacturing, and Education modernize their data infrastructure with confidence.
Axalin's AWS Glue and data integration services include:
- AWS Glue Pipeline Architecture & Design: Axalin's certified AWS professionals architect serverless ETL pipelines tailored to your data volumes, source systems, and business KPIs — ensuring scalable, future-proof designs from day one.
- Glue Studio Implementation & Automation: From setting up the Data Catalog and configuring Glue Crawlers to building visual ETL workflows in Glue Studio, Axalin manages the full implementation lifecycle.
- Cloud Migration & Data Lake Strategy: Axalin's Cloud Adoption and Migration practice helps you move on-premises data stores to AWS — integrating AWS Glue, Amazon S3, Redshift, and Athena into a cohesive, analytics-ready architecture.
- Managed Cloud Solutions: Through its Managed Cloud Solutions offering, Axalin provides ongoing monitoring, optimization, and support for your AWS Glue environment — including proactive cost management to keep your data pipelines lean and efficient.
- AI Automation and Orchestration: Axalin's Application and Innovation practice leverages AWS Glue's generative AI capabilities alongside broader automation and orchestration tools to build intelligent, self-healing data pipelines.
- Strategic Talent Solutions: Need AWS-certified data engineers? Axalin's Strategic Talent Solutions — including Offshore Staff Augmentation and Onshore Staff Augmentation — gives you access to a dedicated pool of AWS Glue and data engineering experts, on demand.
Axalin's differentiating approach lies in its unwavering commitment to custom, tailor-made solutions. The team understands that no two businesses share the same IT vision. Every engagement is handled with a dedicated account manager, multi-vendor certified professionals, and a flexible Build-Operate-Transfer (BOT) engagement model — giving clients both immediate execution capability and long-term technology ownership.
With cloud platform partnerships spanning Amazon Web Services, Microsoft Azure, Google Cloud, and Digital Ocean — and application partnerships with SAP, Oracle, Microsoft, Splunk, and Atlassian — Axalin brings a vendor-agnostic perspective to every data modernization engagement. The result: the right tool for the right job, every time.
Conclusion: Future-Proof Your Data Strategy with AWS Glue and Axalin Consultancy Services
AWS Glue represents a fundamental shift in how organizations approach data integration. By removing infrastructure complexity, automating ETL workflows, and scaling on demand, it empowers data teams to spend less time wrangling pipelines and more time generating insights that drive real business value.
Its serverless architecture, built-in AI capabilities, and deep integration with the broader AWS ecosystem make it one of the most powerful managed ETL services available today — suitable for start-ups processing gigabytes and enterprises managing petabytes alike.
Yet technology alone does not guarantee results. The true value of AWS Glue is realized when it is architected thoughtfully, governed proactively, and continuously optimized by people who understand both the technology and your business goals.
That is the promise of Axalin Consultancy Services — blending deep technical expertise with sharp business insight to help organizations across every industry unlock technology's full potential. Whether you are embarking on your first AWS Glue implementation, optimizing a cost-bloated pipeline, or modernizing an entire data estate, Axalin's team of certified professionals is ready to guide you every step of the way.
Ready to transform your data infrastructure? Partner with Axalin Consultancy Services today — and turn your data from a challenge into your most powerful competitive advantage.